爬虫
记一次爬浙江省教育考试院 2019届选考科目要求
- 主要学习bs4的使用
步骤
先从 http://zt.zjzs.net/xk2020/allcollege.html 上面爬下学校的基本信息
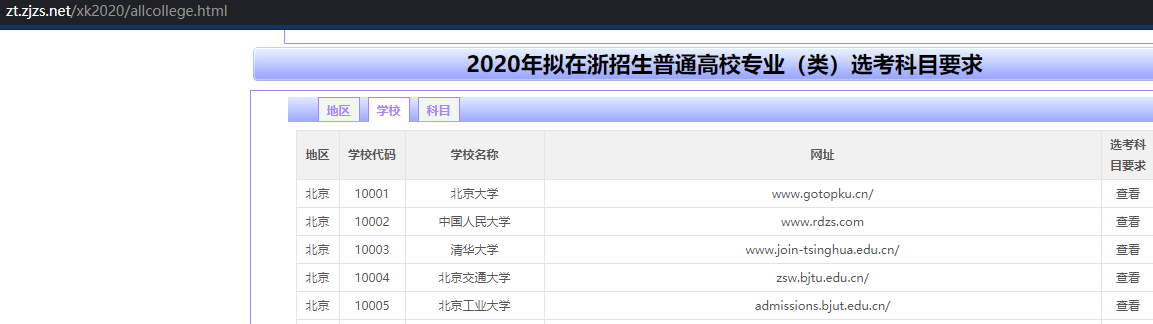
学校地区 学校代码 学校名称 学校网址 对应选考科目网址
将对应选考科目网址加到list里,然后遍历
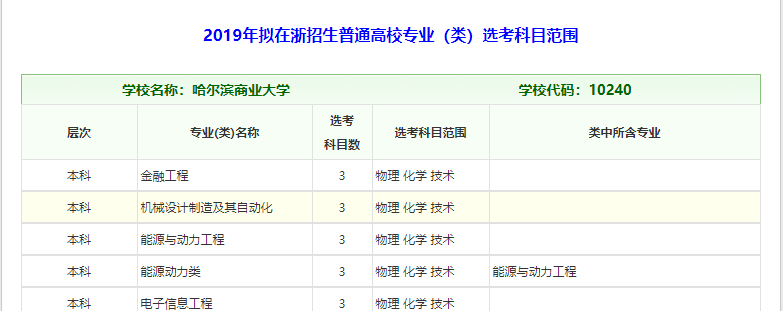
保存学校名称 学校代码 层次 专业名称 选考科目数 选考科目范围 类中所含专业
保存内容到csv里
里面好像学到的东西
BeautifulSoup
from bs4 import BeautifulSoup
r = requests.get(url=url)
soup = BeautifulSoup(r.content, features="html.parser")
coll = soup.find_all('tr', attrs={'bgcolor': '#FFFFFF'}find_all 前面一个参数是标签,后面是属性,如果为了省事就是写成attrs,里面成对的写就行,得到一个list
(bs4.element.Tag).get(‘href’) .get可以得到指定属性的值
.get_text() 可以得到一对标签内的 内容
csv
import csv
csvhead = ['college_name', 'college_num', 'college_type', 'major', 'need_xuan_num', 'need_xuan_name', 'major_include']
with open('detail.csv', 'w+', newline='')as f:
f_csv = csv.writer(f)
f_csv.writerow(csvhead)
f_csv.writerow(li)# li是一个list
f_csv.writerows(lis)# lis是一堆list代码
import requests
import csv
import time
from bs4 import BeautifulSoup
url = 'http://zt.zjzs.net/xk2019/'
csvhead = ['college_name', 'college_num', 'college_type', 'major', 'need_xuan_num', 'need_xuan_name', 'major_include']
li = []
r = requests.get(url=url + 'allcollege.html')
soup = BeautifulSoup(r.content, features="html.parser")
coll = soup.find_all('tr', attrs={'bgcolor': '#FFFFFF'})
for c in coll:
ctd = c.find_all('td')
li.append(ctd[4].a.get('href'))
# , encoding='utf-8'
with open('detail.csv', 'w+', newline='')as f:
f_csv = csv.writer(f)
# f_csv.writerow(csvhead)
for ur in li:
time.sleep(0.2)
college_r = requests.get(url=url + ur)
content=college_r.content.replace(b'<br/>',b' ')
content=content.replace(b'\n',b' ')
soup = BeautifulSoup(content, features="html.parser")
divtitle = soup.find_all('div', class_='subTitle')
college_name = divtitle[0].find_all('div')[0].get_text().split(':')[1].strip()
college_num = divtitle[0].find_all('div')[1].get_text().split(':')[1].strip()
# print(college_name)
# print(college_num)
coll = soup.find_all('tr', attrs={'bgcolor': '#FFFFFF'})
for c in coll:
ctd = c.find_all('td')
li = [college_name, college_num, ctd[0].get_text(), ctd[1].get_text(), ctd[2].get_text(), ctd[3].get_text(),
ctd[4].get_text().strip('\xa0')]
# 港中大的有点问题,所以要strip('\xa0')
print(li)
f_csv.writerow(li)
# li = [ctd[0].get_text(), ctd[1].get_text(), ctd[2].get_text(), ctd[3].a.get('href'), ctd[4].a.get('href')]第二次爬杭电教务处xlsx数据
没学啥新东西
后来发现有简单办法 wget 下载指定url路径下的 指定类型的(全部)文件
wget http://mirrors.ustc.edu.cn/ubuntu/pool/main/g/gcc-4.4/ -r -np -nd -A .deb -e robots=off wget http://mirrors.ustc.edu.cn/ubuntu/pool/universe/g/gcc-3.3/ -r -np -nd -A .deb -e robots=off wget http://mirrors.ustc.edu.cn/ubuntu/pool/main/liba/libaio/ -r -np -nd -A .deb -e robots=off wget http://mirrors.ustc.edu.cn/ubuntu/pool/main/m/mpfr4/libmpfr4_3.1.6-1_amd64.deb -r:层叠递归处理 -np:不向上(url路径)递归 -nd:不创建和web网站相同(url路径)的目录结构 -A type:文件类型 -e robots=off:不考虑 robots.txt 的权限
思路
- 两个list,一个是没访问过的,一个是访问过的
- 不断访问解析没有访问过list,然后再检测网页里的url,发现是xlsx就直接下载,其他用filter过滤一下,只选择本地的站点,加到未访问过的list
- 最后为了搜索方便,把xlsx转csv
好像学到的东西
xlsx转csv
但实际上因为编码问题,转换不成功
import pandas as pd
import os
def xlsx_to_csv_pd(filename):
data_xls = pd.read_excel(filename, index_col=0)
data_xls.to_csv(filename.split('.')[0]+'.csv')
for f in os.listdir('./'):
if f.endswith('.xlsx'):
print(f)
xlsx_to_csv_pd(f)代码
# 爬杭电教务处东西
from bs4 import BeautifulSoup
import time
import json
import csv
import requests
def filterurl(url):
url = str(url.get('href'))
if url[0] == '/':
return True
if 'jwc.hdu.edu.cn' in url:
return True
return False
url = 'http://jwc.hdu.edu.cn'
unvisited_site = ['http://jwc.hdu.edu.cn/2019/0923/c4524a102043/page.htm']
visited_site = []
for ur in unvisited_site:
time.sleep(0.2)
if ur in visited_site:
continue
if 'upload' in ur:
continue
try:
visited_site.append(ur)
unvisited_site.remove(ur)
except:
pass
if ur[0]=='/':
ur=url+ur
r = requests.get(url=ur)
try:
soup = BeautifulSoup(r.content, features="html.parser")
all_a = soup.find_all('a')
right_url = filter(filterurl, all_a)
for aa in right_url:
if str(aa.get('href')).endswith('.x1sx') or str(aa.get('href')).endswith('.xlsx') or str(aa.get('href')).endswith('.xls'):
filename = soup.find('a', attrs={'href': str(aa.get('href'))}).get_text()
fr = requests.get(url=url + str(aa.get('href')))
print(str(aa.get('href')))
with open(filename + '.xlsx', 'wb') as ff:
ff.write(fr.content)
visited_site.append(str(aa.get('href')))
else:
if str(aa.get('href')) not in visited_site and str(aa.get('href')) not in unvisited_site:
unvisited_site.append(str(aa.get('href')))
except:
pass
一些基础用法
参考 https://www.cnblogs.com/tjp40922/p/10428447.html
基础巩固:
(1)根据标签名查找
- soup.a 只能找到第一个符合要求的标签
(2)获取属性
- soup.a.attrs 获取a所有的属性和属性值,返回一个字典
- soup.a.attrs['href'] 获取href属性
- soup.a['href'] 也可简写为这种形式
(3)获取内容
- soup.a.string 获取a标签的直系文本
- soup.a.text 这是属性,获取a子类的所有文本
- soup.a.get_text() 这是方法,获取a标签子类的所有文本
【注意】如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容
(4)find:找到第一个符合要求的标签
- soup.find('a') 找到第一个符合要求的
- soup.find('a', title="xxx") 具有title=a属性的
- soup.find('a', alt="xxx")
- soup.find('a', class_="xxx")
- soup.find('a', id="xxx")
(5)find_all:找到所有符合要求的标签
- soup.find_all('a')
- soup.find_all(['a','b']) 找到所有的a和b标签
- soup.find_all('a', limit=2) 限制前两个
(6)根据选择器选择指定的内容
select:soup.select('#feng')
- 常见的选择器:标签选择器(a)、类选择器(.)、id选择器(#)、层级选择器
- 层级选择器:
div .dudu #lala .meme .xixi 下面好多级
div > p > a > .lala 只能是下面一级
select就是css选择器
【注意】select选择器返回永远是列表,需要通过下标提取指定的对象后记
后来发现浏览器中这种简单的提取,直接用xpath或者选择提取写代码更方便
不仅可以用于bs4 还可以用selenium进行自动化测试
f12打开控制台,选择要提取的标签,右键copy
# 复制来的东西长这样
/html/body/div[1]/div/div[1]/div[2]/div[6]/pre/code
#zhengwen > div:nth-child(15) > pre > code
# 然后这样直接就可以提取内容
browser.find_elements_by_xpath('/html/body/div[1]/div/div[1]/div[2]/div[6]/pre/code').text其实第二次爬取是比较失败的,效果不是很好,而且是可以直接用wget工具做的,自己浪费了很多时间